

The global peptide therapeutics landscape, surging towards a $75 billion valuation, is at an inflection point where biological complexity meets data abundance. While the industry generates terabytes of data from high-throughput screening, omics technologies, and real-world evidence, fewer than 15% of peptide companies have a cohesive strategy to harness this information, leaving an estimated $2.1 billion in annual R&D efficiency and commercial value untapped.
A deliberate digital strategy integrating Artificial Intelligence (AI), Machine Learning (ML), and advanced data analytics is no longer a futuristic concept but an immediate operational imperative, proven to accelerate discovery timelines by 30-50%, improve manufacturing yield by 20-35%, and unlock personalized treatment paradigms. This definitive guide provides a phased implementation roadmap, empowering peptide organizations to transition from data-rich but insight-poor entities to AI-driven, digitally native pioneers poised to dominate the next era of biomedicines.
The Digital Imperative: Transforming Data from Byproduct to Strategic Asset
The traditional linear model of peptide R&D and commercialization is buckling under the weight of data and complexity, creating a burning platform for digital transformation.
The Cost of Inaction: Stagnation in a Data-Driven Era
Organizations lacking a digital strategy face critical vulnerabilities:
- Inefficient R&D Spend: 85-90% of clinical candidate peptides fail, with poor target validation and pharmacokinetic prediction as key culprits—areas where AI excels.
- Suboptimal Manufacturing: Reactive, batch-based process control leads to variable yields and quality, eroding margins in a cost-sensitive market.
- Blinded Commercialization: Inability to segment patient populations or predict prescriber behavior limits market uptake and lifecycle management.
- Talent Drain: Top data scientists and computational biologists seek employers with modern tech stacks and a vision for data-centric discovery.
The Pillars of a Peptide Digital Strategy
A successful strategy rests on three interconnected foundations:
- Technology & Infrastructure: Scalable cloud compute, unified data lakes, and modular AI/ML platforms.
- Data Governance & Curation: Standards for FAIR (Findable, Accessible, Interoperable, Reusable) data, spanning from chemical synthesis parameters to clinical outcomes.
- People & Process: Cross-functional “translational” teams blending peptide science, data science, and IT, supported by agile workflows.
“Implementing AI in peptide R&D isn’t about buying a software license. It’s about orchestrating a cultural and operational metamorphosis. The roadmap must be less of a Gantt chart for IT and more of a change management plan for the entire organization, where data becomes the universal language of innovation.” — Dr. Kenji Tanaka, Chief Digital Officer, Global Biopharma Innovations.
A Phased Implementation Roadmap: From Foundation to Autonomy
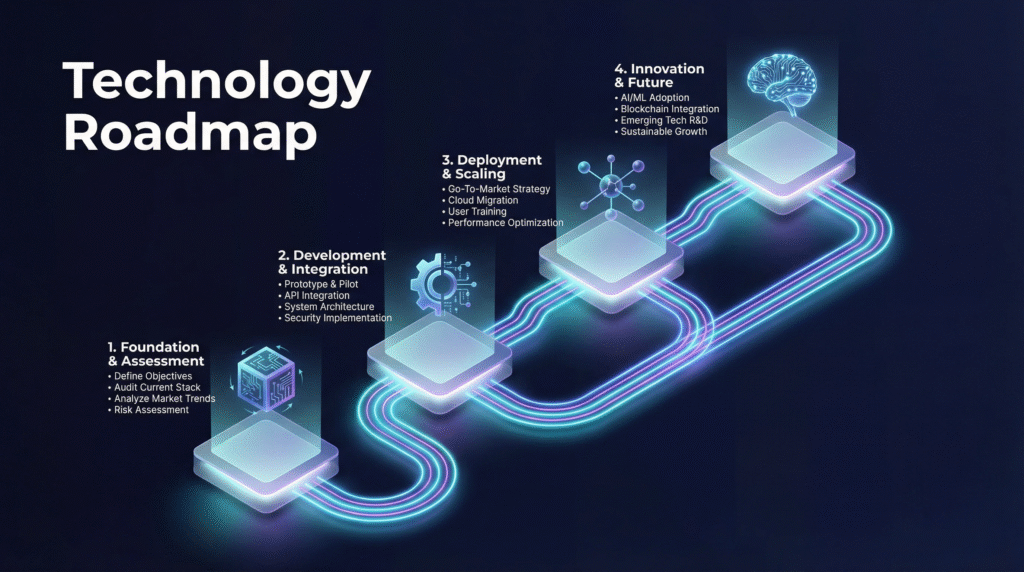
A successful digital transformation is a marathon, not a sprint. A four-phase roadmap ensures sustainable, value-driven progress.
Phase 1: Foundation & Assessment (Months 0-6)
Lay the groundwork for scalable success.
| Objective | Key Activities | Success Metrics |
|---|---|---|
| Digital Maturity Audit | Map current data sources, systems, and skills. Identify 2-3 high-value, feasible use cases (e.g., peptide property prediction, chromatogram analysis). | Prioritized use case portfolio with defined ROI hypotheses. |
| Data Foundation | Establish core data governance council. Initiate key data curation projects (e.g., historic synthesis data digitization). Select cloud provider (AWS, GCP, Azure). | Existence of a data catalog; first datasets migrated to a cloud data lake. |
| Team Formation | Appoint a Digital Product Leader. Form a pilot cross-functional squad with a computational chemist, a data engineer, and a biologist. | Pilot team operational with a clear charter and 6-month goals. |
Phase 2: Pilot & Prove Value (Months 6-18)
Demonstrate tangible impact to secure buy-in and funding.
- Execute Pilot Projects: Focus on a single, high-confidence use case. Example: Build an ML model to predict peptide solubility/aggregation propensity from sequence, reducing late-stage formulation failures.
- Adopt an MLOps Lite Framework: Implement basic version control for models and data, ensuring reproducibility.
- Measure and Broadcast Success: Quantify time or cost savings from the pilot. Present results to senior leadership and the broader R&D organization.
- Output: 1-2 production-ready AI tools with documented ROI; expanded stakeholder support.
Phase 3: Scale & Industrialize (Months 18-36)
Systematize success and expand across the value chain.
- Scale Infrastructure: Implement a full MLOps platform (e.g., Domino, Dataiku) for automated model training, deployment, and monitoring.
- Expand Use Cases: Launch parallel squads targeting process analytics (PAT for manufacturing), clinical trial biomarker identification, and commercial analytics.
- Upskill the Workforce: Launch mandatory data literacy programs for scientists and “citizen data science” training for power users.
- Output: A center of excellence (CoE); 5-10 deployed models impacting multiple functions; a data-driven culture becoming the norm.
Phase 4: Autonomous Innovation (Month 36+)
Achieve a sustainable competitive advantage through embedded intelligence.
- Predictive & Adaptive Operations: Moving from descriptive to prescriptive analytics (e.g., AI recommending new peptide leads for a target, or auto-optimizing a purification process).
- Data as a Product: Treated internal data assets as products, with dedicated teams ensuring their quality and accessibility for innovation.
- Ecosystem Integration: Securely sharing data and models with academic and CRO partners to create a superior external innovation network.
Core Application Areas: Where AI/ML Drives Peptide-Specific Value
The technology must solve domain-specific problems. Here’s how it applies across the peptide lifecycle.
1. AI-Augmented Discovery and Design
Accelerating the journey from target to candidate.
| Application | Technology/Task | Potential Impact |
|---|---|---|
| De Novo Peptide Design | Generative AI models (e.g., VAEs, GANs, Diffusion Models) trained on known peptide structures/activities to propose novel, optimized sequences. | Explore vast chemical space beyond human intuition; design peptides with multi-property optimization (potency, stability, specificity). |
| Property Prediction (ADMET) | ML models (Random Forest, GNNs) predicting permeability, metabolic stability, and immunogenicity from sequence and structural descriptors. | Reduce synthesis and testing of low-probability candidates by 50%, focusing resources. |
| Target-Peptide Interaction Modeling | Deep learning for protein-peptide docking and binding affinity prediction, reducing reliance on costly experimental structural biology early on. | Higher confidence in mechanism of action, faster lead optimization cycles. |
2. Smart Manufacturing and Process Analytics
Driving consistency, yield, and quality in production.
- Predictive Process Control: Using historical batch data to build ML models that predict critical quality attributes (CQAs), enabling real-time parameter adjustment.
- Advanced Process Analytical Technology (PAT): ML algorithms analyzing real-time spectroscopy (Raman, NIR) data to monitor peptide concentration, purity, and aggregation during synthesis and purification.
- Root Cause Analysis: AI-driven analysis of deviation and batch failure data to identify subtle, interacting process parameters that human investigators might miss.
3. Clinical Development and Personalized Medicine
Enhancing trial efficiency and tailoring therapies.
- Clinical Trial Optimization: AI for site selection, patient recruitment prediction, and dynamic risk-based monitoring, reducing trial duration and cost.
- Biomarker Discovery: ML analysis of multi-omics data from trials to identify patient subpopulations most likely to respond to a peptide therapy (predictive biomarkers).
- Real-World Evidence (RWE) Analytics: NLP and ML to extract insights from electronic health records (EHRs) on real-world effectiveness, safety, and unmet needs.
Building the Data Foundation: Governance, Architecture, and Talent
The most advanced AI algorithms are useless without high-quality, accessible data.
Data Architecture for the Modern Peptide Enterprise
- Unified Data Lake: A centralized, cloud-based repository (e.g., on AWS S3, Azure Data Lake) holding raw data from all domains: chemical registries, ELNs, LIMS, clinical databases, commercial data.
- Semantic Layer & Ontologies: Implementing controlled vocabularies and peptide-specific ontologies to ensure a “peptide” in discovery means the same thing as in manufacturing or clinical reports.
- API-First Integration: Moving beyond fragile point-to-point connections to APIs that allow systems (ELN, LIMS, CDS) to publish and consume data seamlessly.
The Human Element: Building Cross-Functional Teams
The “translational data scientist” is key:
- Team Model: Embedded, cross-functional product teams (a “squad”) with a product owner, data engineer, ML engineer, data scientist, and domain scientist (peptide chemist, biologist).
- Skills Development: Upskilling biologists in data literacy and data scientists in peptide science fundamentals through joint projects and training.
- Career Pathways: Creating clear “dual-track” career ladders for computational experts within the R&D organization, not just within IT.
Future Trends: The Next Horizon of Peptide Informatics
The field is moving towards more integrated, autonomous, and generative systems.
Emerging Technological Frontiers
- Foundation Models for Peptides: Large language models (like GPT, but for protein/peptide sequences) pre-trained on all known peptide data, fine-tunable for specific discovery tasks with limited data.
- Digital Twins: Creating dynamic, computational models of a peptide process (e.g., a manufacturing line, a patient’s physiological response) to simulate scenarios and optimize outcomes in silico before real-world execution.
- AI-Driven Synthesis Planning: Systems that not only design peptides but also plan the optimal synthetic route (SPPS, LPPS, recombinant) and predict required protecting groups.
Evolving Business Models
- Data-as-a-Service (DaaS): Monetizing curated, high-value peptide datasets or pre-trained models for the broader research community.
- AI-Powered Platforms as Differentiators: For CDMOs, offering AI-accelerated process development as a premium service to attract clients.
FAQs: Implementing AI and Data Analytics in Peptide Organizations
Q: We are a mid-sized biotech with limited budget. Where should we absolutely not cut corners when starting our AI journey?
A: The areas not to compromise are: 1) Data Curation: Garbage in, garbage out. Invest time in cleaning and standardizing the data for your first pilot. A small, high-quality dataset beats a large, messy one. 2) Cross-Functional Team: Do not let IT run this alone or outsource it completely. The dedicated time of an in-house peptide scientist who deeply understands the problem is non-negotiable for success. 3) Clear Problem Definition: Start with a well-scoped, valuable business problem (“predict peptide solubility to reduce late-stage attrition”), not a technology in search of a problem (“implement a neural network”).
You can use open-source ML libraries and modest cloud compute, but you cannot shortcut on data quality, domain expertise, and problem focus.
Q: How do we measure the ROI of our digital and AI initiatives, especially in early-stage R&D where the payoff is years away?
A: Measure a combination of leading and lagging indicators. Lagging indicators (e.g., number of INDs filed, cycle time reduction) will take time. For early-phase justification, track leading indicators: Efficiency Gains: Reduction in experiments needed to reach a candidate (e.g., “ML pre-screening eliminated 70% of low-potential sequences”).
Improved Decision Quality: Higher success rate in moving from one stage to the next (e.g., “80% of ML-prioritized peptides showed the desired activity in vitro vs. 20% historical rate”). Cost Avoidance: Quantifying the cost of experiments or clinical delays avoided by better predictions. Frame the ROI not just as cost savings, but as increased probability of technical success and faster time to market for your entire portfolio.
Q: How do we handle data privacy and IP security when using cloud-based AI/ML platforms and external data?
A: This requires a proactive security-by-design approach. For Cloud: Use dedicated virtual private clouds (VPCs), encrypt all data at rest and in transit, and strictly manage access with IAM roles. Major cloud providers have compliance programs (HIPAA, GxP) tailored for life sciences. For IP: Ensure contracts with cloud/software vendors explicitly state that you retain all IP rights to your data, trained models, and generated outputs. For sensitive model training, consider techniques like federated learning, where the model is sent to your secure data, not vice-versa. Always conduct a formal risk assessment with legal and cybersecurity teams before procuring any external platform.
Core Takeaways
- Strategy First, Technology Second: Successful implementation requires a clear business-aligned strategy and roadmap, not an ad-hoc collection of AI projects.
- Phased, Value-Driven Approach: Begin with a solid foundation, prove value with targeted pilots, scale systematically, and aim for autonomous, embedded intelligence. Celebrate and communicate quick wins.
- Data is the Foundational Asset: Investing in FAIR data governance, curation, and a modern cloud data architecture is a prerequisite for any advanced analytics, not an optional IT project.
- Cross-Functional Teams are the Engine: Breaking down silos between data scientists and peptide domain experts is the single greatest predictor of translational success.
- Competitive Necessity: In the race to develop better peptides faster and cheaper, a robust digital strategy powered by AI/ML is transitioning from a competitive advantage to a table stake for survival and growth.
Conclusion: Charting the Course to a Data-Driven Future
The integration of AI, ML, and data analytics represents the most significant lever for innovation and efficiency in the modern peptide industry. The journey from data chaos to insight-driven discovery and operations is complex, requiring deliberate planning, investment, and cultural shift. However, the rewards—accelerated therapies for patients, more sustainable and profitable manufacturing, and a formidable competitive moat—are unparalleled.
By following a structured roadmap, focusing on high-impact use cases, and nurturing the crucial partnership between human expertise and machine intelligence, peptide companies can transform the immense challenge of biological complexity into their greatest opportunity. The future of peptide therapeutics will be written not only in the language of amino acids but in the binary code of intelligent, data-empowered science.
Disclaimer
This article contains information, data, and references that have been sourced from various publicly available resources on the internet. The purpose of this article is to provide educational and informational content. All trademarks, registered trademarks, product names, company names, or logos mentioned within this article are the property of their respective owners. The use of these names and logos is for identification purposes only and does not imply any endorsement or affiliation with the original holders of such marks. The author and publisher have made every effort to ensure the accuracy and reliability of the information provided.
However, no warranty or guarantee is given that the information is correct, complete, or up-to-date. The views expressed in this article are those of the author and do not necessarily reflect the views of any third-party sources cited.


